Recent advancements in robotic manipulation have highlighted the potential of intermediate representations for improving policy generalization. In this work, we explore grounding masks as an effective intermediate representation, balancing two key advantages: (1) effective spatial guidance that specifies target objects and placement areas while also conveying information about object shape and size, and (2) broad generalization potential driven by large-scale vision-language models pretrained on diverse grounding datasets. We introduce \method, a grounding-aware robotic manipulation policy that leverages grounding masks as an intermediate representation to guide policy networks in object manipulation tasks. To further explore and enhance generalization, we propose an automated pipeline for generating large-scale, simulated data with a diverse set of objects and instructions. Extensive experiments show the value of our dataset and the effectiveness of grounding masks as intermediate guidance, significantly enhancing the generalization abilities of robot policies.
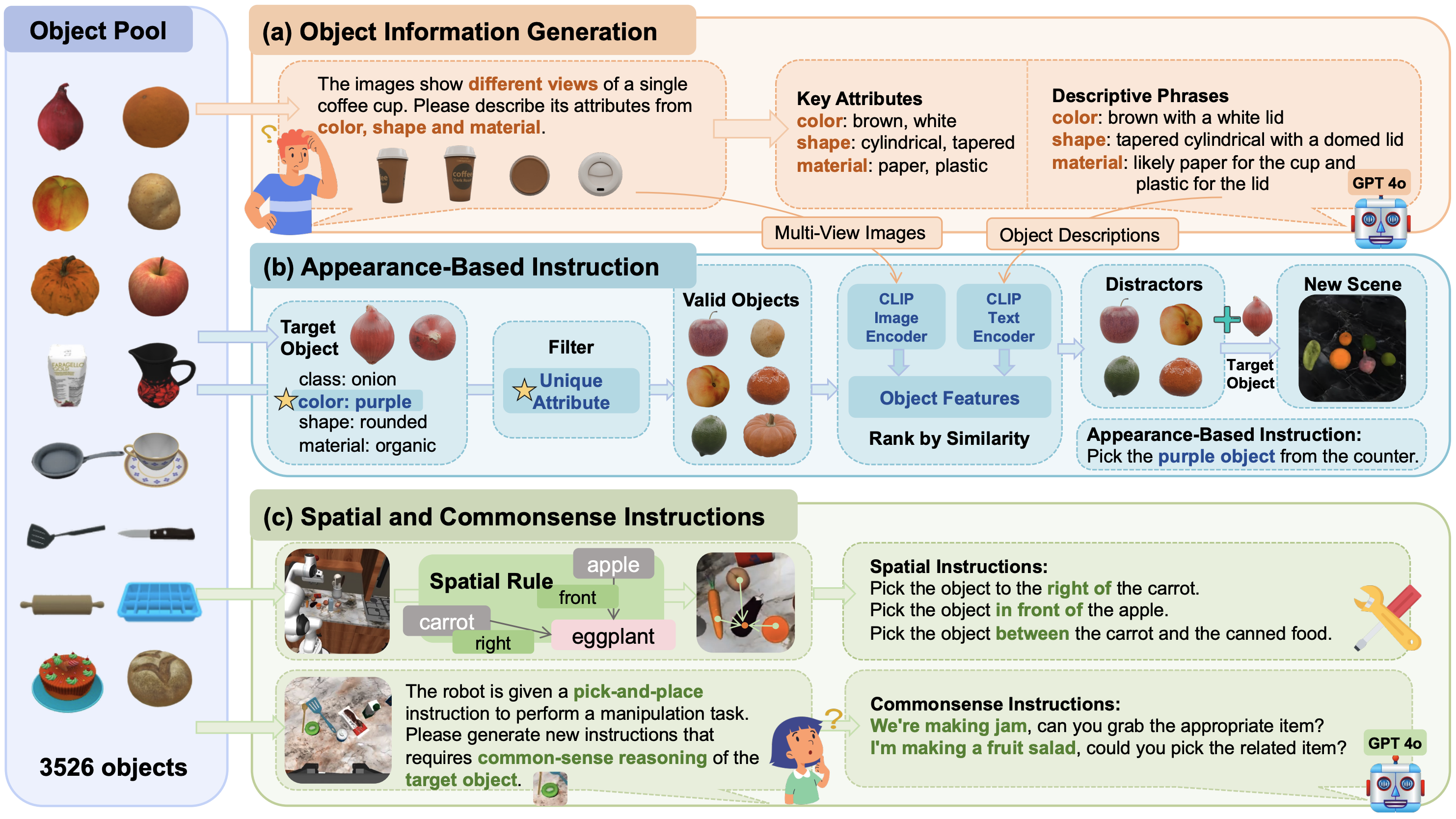
The pipeline is composed of three key stages: (a) First, we extract informative object attributes in both keyword and descriptive phrase formats; (b) Next, appearance-based instructions are generated using these attributes, where keywords filter objects and descriptive phrases calculate appearance similarity; (c) Finally, spatial and commonsense instructions are generated through rule-based methods and GPT-generated techniques, respectively.
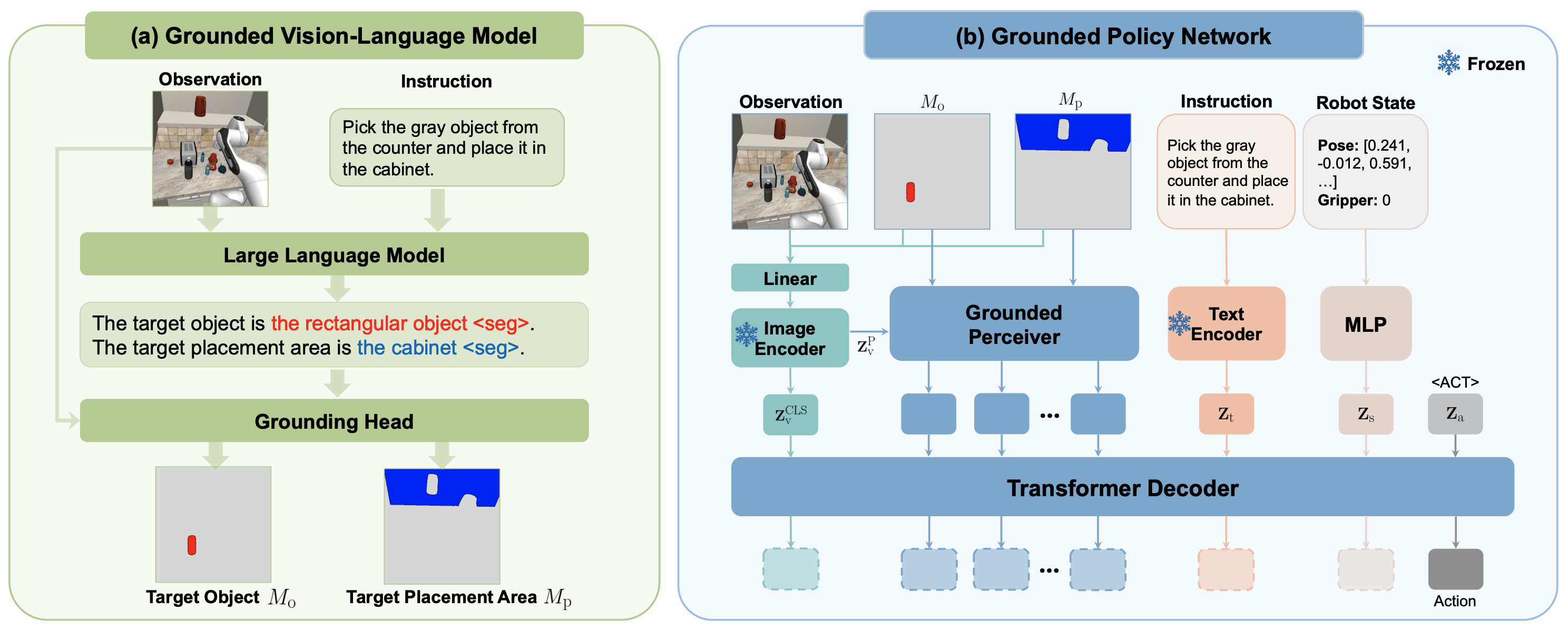
To enhance policy generalization, we leverage grounding masks as intermediate representations for spatial guidance. Specifically, (a) The grounded vision-language model processes the instruction and image observation to generate target masks. (b) The grounded policy network integrates mask guidance by concatenating masks with the image input and directing attention within the grounded perceiver.
@misc{huang2025robogroundroboticmanipulationgrounded,
title={RoboGround: Robotic Manipulation with Grounded Vision-Language Priors},
author={Haifeng Huang and Xinyi Chen and Yilun Chen and Hao Li and Xiaoshen Han and Zehan Wang and Tai Wang and Jiangmiao Pang and Zhou Zhao},
year={2025},
eprint={2504.21530},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2504.21530},
}